Monte Carlo Integration¶
This chapter describes routines for multidimensional Monte Carlo integration. These include the traditional Monte Carlo method and adaptive algorithms such as VEGAS and MISER which use importance sampling and stratified sampling techniques. Each algorithm computes an estimate of a multidimensional definite integral of the form,
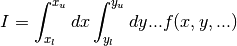
over a hypercubic region 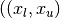 ,
, 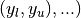 using
a fixed number of function calls. The routines also provide a
statistical estimate of the error on the result. This error estimate
should be taken as a guide rather than as a strict error bound—random
sampling of the region may not uncover all the important features
of the function, resulting in an underestimate of the error.
using
a fixed number of function calls. The routines also provide a
statistical estimate of the error on the result. This error estimate
should be taken as a guide rather than as a strict error bound—random
sampling of the region may not uncover all the important features
of the function, resulting in an underestimate of the error.
The functions are defined in separate header files for each routine,
gsl_monte_plain.h, gsl_monte_miser.h and
gsl_monte_vegas.h.
Interface¶
All of the Monte Carlo integration routines use the same general form of interface. There is an allocator to allocate memory for control variables and workspace, a routine to initialize those control variables, the integrator itself, and a function to free the space when done.
Each integration function requires a random number generator to be supplied, and returns an estimate of the integral and its standard deviation. The accuracy of the result is determined by the number of function calls specified by the user. If a known level of accuracy is required this can be achieved by calling the integrator several times and averaging the individual results until the desired accuracy is obtained.
Random sample points used within the Monte Carlo routines are always chosen strictly within the integration region, so that endpoint singularities are automatically avoided.
The function to be integrated has its own datatype, defined in the
header file gsl_monte.h.
-
type gsl_monte_function¶
This data type defines a general function with parameters for Monte Carlo integration.
double (* f) (double * x, size_t dim, void * params)this function should return the value
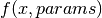 for the argument
for the argument
xand parametersparams, wherexis an array of sizedimgiving the coordinates of the point where the function is to be evaluated.size_t dimthe number of dimensions for
x.void * paramsa pointer to the parameters of the function.
Here is an example for a quadratic function in two dimensions,
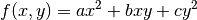
with 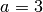 ,
, 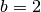 ,
, 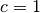 . The following code
defines a
. The following code
defines a gsl_monte_function F which you could pass to an
integrator:
struct my_f_params { double a; double b; double c; };
double
my_f (double x[], size_t dim, void * p) {
struct my_f_params * fp = (struct my_f_params *)p;
if (dim != 2)
{
fprintf (stderr, "error: dim != 2");
abort ();
}
return fp->a * x[0] * x[0]
+ fp->b * x[0] * x[1]
+ fp->c * x[1] * x[1];
}
gsl_monte_function F;
struct my_f_params params = { 3.0, 2.0, 1.0 };
F.f = &my_f;
F.dim = 2;
F.params = ¶ms;
The function 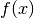 can be evaluated using the following macro:
can be evaluated using the following macro:
#define GSL_MONTE_FN_EVAL(F,x)
(*((F)->f))(x,(F)->dim,(F)->params)
PLAIN Monte Carlo¶
The plain Monte Carlo algorithm samples points randomly from the
integration region to estimate the integral and its error. Using this
algorithm the estimate of the integral  for
for 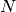 randomly distributed points
randomly distributed points 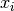 is given by,
is given by,
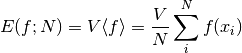
where 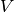 is the volume of the integration region. The error on
this estimate
is the volume of the integration region. The error on
this estimate 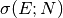 is calculated from the estimated
variance of the mean,
is calculated from the estimated
variance of the mean,
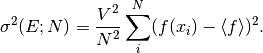
For large this variance decreases asymptotically as
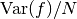 , where
, where 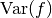 is the true variance of the
function over the integration region. The error estimate itself should
decrease as
is the true variance of the
function over the integration region. The error estimate itself should
decrease as 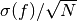 .
The familiar law of errors
decreasing as
.
The familiar law of errors
decreasing as 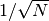 applies—to reduce the error by a
factor of 10 requires a 100-fold increase in the number of sample
points.
applies—to reduce the error by a
factor of 10 requires a 100-fold increase in the number of sample
points.
The functions described in this section are declared in the header file
gsl_monte_plain.h.
-
type gsl_monte_plain_state¶
This is a workspace for plain Monte Carlo integration
-
gsl_monte_plain_state *gsl_monte_plain_alloc(size_t dim)¶
This function allocates and initializes a workspace for Monte Carlo integration in
dimdimensions.
-
int gsl_monte_plain_init(gsl_monte_plain_state *s)¶
This function initializes a previously allocated integration state. This allows an existing workspace to be reused for different integrations.
-
int gsl_monte_plain_integrate(gsl_monte_function *f, const double xl[], const double xu[], size_t dim, size_t calls, gsl_rng *r, gsl_monte_plain_state *s, double *result, double *abserr)¶
This routines uses the plain Monte Carlo algorithm to integrate the function
fover thedim-dimensional hypercubic region defined by the lower and upper limits in the arraysxlandxu, each of sizedim. The integration uses a fixed number of function callscalls, and obtains random sampling points using the random number generatorr. A previously allocated workspacesmust be supplied. The result of the integration is returned inresult, with an estimated absolute errorabserr.
-
void gsl_monte_plain_free(gsl_monte_plain_state *s)¶
This function frees the memory associated with the integrator state
s.
MISER¶
The MISER algorithm of Press and Farrar is based on recursive stratified sampling. This technique aims to reduce the overall integration error by concentrating integration points in the regions of highest variance.
The idea of stratified sampling begins with the observation that for two
disjoint regions  and
and  with Monte Carlo estimates of the
integral
with Monte Carlo estimates of the
integral 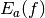 and
and 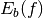 and variances
and variances
 and
and 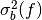 , the variance
of the combined estimate
, the variance
of the combined estimate
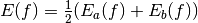 is given by,
is given by,
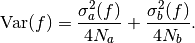
It can be shown that this variance is minimized by distributing the points such that,
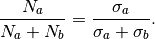
Hence the smallest error estimate is obtained by allocating sample points in proportion to the standard deviation of the function in each sub-region.
The MISER algorithm proceeds by bisecting the integration region
along one coordinate axis to give two sub-regions at each step. The
direction is chosen by examining all 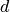 possible bisections and
selecting the one which will minimize the combined variance of the two
sub-regions. The variance in the sub-regions is estimated by sampling
with a fraction of the total number of points available to the current
step. The same procedure is then repeated recursively for each of the
two half-spaces from the best bisection. The remaining sample points are
allocated to the sub-regions using the formula for
possible bisections and
selecting the one which will minimize the combined variance of the two
sub-regions. The variance in the sub-regions is estimated by sampling
with a fraction of the total number of points available to the current
step. The same procedure is then repeated recursively for each of the
two half-spaces from the best bisection. The remaining sample points are
allocated to the sub-regions using the formula for  and
and
 . This recursive allocation of integration points continues
down to a user-specified depth where each sub-region is integrated using
a plain Monte Carlo estimate. These individual values and their error
estimates are then combined upwards to give an overall result and an
estimate of its error.
. This recursive allocation of integration points continues
down to a user-specified depth where each sub-region is integrated using
a plain Monte Carlo estimate. These individual values and their error
estimates are then combined upwards to give an overall result and an
estimate of its error.
The functions described in this section are declared in the header file
gsl_monte_miser.h.
-
type gsl_monte_miser_state¶
This workspace is used for MISER Monte Carlo integration
-
gsl_monte_miser_state *gsl_monte_miser_alloc(size_t dim)¶
This function allocates and initializes a workspace for Monte Carlo integration in
dimdimensions. The workspace is used to maintain the state of the integration.
-
int gsl_monte_miser_init(gsl_monte_miser_state *s)¶
This function initializes a previously allocated integration state. This allows an existing workspace to be reused for different integrations.
-
int gsl_monte_miser_integrate(gsl_monte_function *f, const double xl[], const double xu[], size_t dim, size_t calls, gsl_rng *r, gsl_monte_miser_state *s, double *result, double *abserr)¶
This routines uses the MISER Monte Carlo algorithm to integrate the function
fover thedim-dimensional hypercubic region defined by the lower and upper limits in the arraysxlandxu, each of sizedim. The integration uses a fixed number of function callscalls, and obtains random sampling points using the random number generatorr. A previously allocated workspacesmust be supplied. The result of the integration is returned inresult, with an estimated absolute errorabserr.
-
void gsl_monte_miser_free(gsl_monte_miser_state *s)¶
This function frees the memory associated with the integrator state
s.
The MISER algorithm has several configurable parameters which can be changed using the following two functions 1.
-
void gsl_monte_miser_params_get(const gsl_monte_miser_state *s, gsl_monte_miser_params *params)¶
This function copies the parameters of the integrator state into the user-supplied
paramsstructure.
-
void gsl_monte_miser_params_set(gsl_monte_miser_state *s, const gsl_monte_miser_params *params)¶
This function sets the integrator parameters based on values provided in the
paramsstructure.
Typically the values of the parameters are first read using
gsl_monte_miser_params_get(), the necessary changes are made to
the fields of the params structure, and the values are copied
back into the integrator state using
gsl_monte_miser_params_set(). The functions use the
gsl_monte_miser_params structure which contains the following
fields:
-
type gsl_monte_miser_params¶
-
double estimate_frac¶
This parameter specifies the fraction of the currently available number of function calls which are allocated to estimating the variance at each recursive step. The default value is 0.1.
-
size_t min_calls¶
This parameter specifies the minimum number of function calls required for each estimate of the variance. If the number of function calls allocated to the estimate using
estimate_fracfalls belowmin_callsthenmin_callsare used instead. This ensures that each estimate maintains a reasonable level of accuracy. The default value ofmin_callsis16 * dim.
-
size_t min_calls_per_bisection¶
This parameter specifies the minimum number of function calls required to proceed with a bisection step. When a recursive step has fewer calls available than
min_calls_per_bisectionit performs a plain Monte Carlo estimate of the current sub-region and terminates its branch of the recursion. The default value of this parameter is32 * min_calls.
-
double alpha¶
This parameter controls how the estimated variances for the two sub-regions of a bisection are combined when allocating points. With recursive sampling the overall variance should scale better than
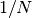 , since the values from the sub-regions will be obtained using
a procedure which explicitly minimizes their variance. To accommodate
this behavior the MISER algorithm allows the total variance to
depend on a scaling parameter
, since the values from the sub-regions will be obtained using
a procedure which explicitly minimizes their variance. To accommodate
this behavior the MISER algorithm allows the total variance to
depend on a scaling parameter 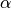 ,
,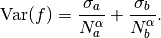
The authors of the original paper describing MISER recommend the value
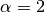 as a good choice, obtained from numerical
experiments, and this is used as the default value in this
implementation.
as a good choice, obtained from numerical
experiments, and this is used as the default value in this
implementation.
-
double dither¶
This parameter introduces a random fractional variation of size
ditherinto each bisection, which can be used to break the symmetry of integrands which are concentrated near the exact center of the hypercubic integration region. The default value of dither is zero, so no variation is introduced. If needed, a typical value ofditheris 0.1.
-
double estimate_frac¶
VEGAS¶
The VEGAS algorithm of Lepage is based on importance sampling. It
samples points from the probability distribution described by the
function 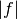 , so that the points are concentrated in the regions
that make the largest contribution to the integral.
, so that the points are concentrated in the regions
that make the largest contribution to the integral.
In general, if the Monte Carlo integral of 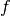 is sampled with
points distributed according to a probability distribution described by
the function
is sampled with
points distributed according to a probability distribution described by
the function  , we obtain an estimate
, we obtain an estimate 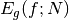 ,
,
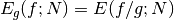
with a corresponding variance,
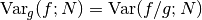
If the probability distribution is chosen as 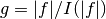 then
it can be shown that the variance
then
it can be shown that the variance 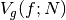 vanishes, and the
error in the estimate will be zero. In practice it is not possible to
sample from the exact distribution for an arbitrary function, so
importance sampling algorithms aim to produce efficient approximations
to the desired distribution.
vanishes, and the
error in the estimate will be zero. In practice it is not possible to
sample from the exact distribution for an arbitrary function, so
importance sampling algorithms aim to produce efficient approximations
to the desired distribution.
The VEGAS algorithm approximates the exact distribution by making a
number of passes over the integration region while histogramming the
function . Each histogram is used to define a sampling
distribution for the next pass. Asymptotically this procedure converges
to the desired distribution. In order
to avoid the number of histogram bins growing like 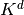 the
probability distribution is approximated by a separable function:
the
probability distribution is approximated by a separable function:
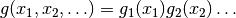 so that the number of bins required is only
so that the number of bins required is only 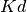 .
This is equivalent to locating the peaks of the function from the
projections of the integrand onto the coordinate axes. The efficiency
of VEGAS depends on the validity of this assumption. It is most
efficient when the peaks of the integrand are well-localized. If an
integrand can be rewritten in a form which is approximately separable
this will increase the efficiency of integration with VEGAS.
.
This is equivalent to locating the peaks of the function from the
projections of the integrand onto the coordinate axes. The efficiency
of VEGAS depends on the validity of this assumption. It is most
efficient when the peaks of the integrand are well-localized. If an
integrand can be rewritten in a form which is approximately separable
this will increase the efficiency of integration with VEGAS.
VEGAS incorporates a number of additional features, and combines both stratified sampling and importance sampling. The integration region is divided into a number of “boxes”, with each box getting a fixed number of points (the goal is 2). Each box can then have a fractional number of bins, but if the ratio of bins-per-box is less than two, Vegas switches to a kind variance reduction (rather than importance sampling).
-
type gsl_monte_vegas_state¶
This workspace is used for VEGAS Monte Carlo integration
-
gsl_monte_vegas_state *gsl_monte_vegas_alloc(size_t dim)¶
This function allocates and initializes a workspace for Monte Carlo integration in
dimdimensions. The workspace is used to maintain the state of the integration.
-
int gsl_monte_vegas_init(gsl_monte_vegas_state *s)¶
This function initializes a previously allocated integration state. This allows an existing workspace to be reused for different integrations.
-
int gsl_monte_vegas_integrate(gsl_monte_function *f, double xl[], double xu[], size_t dim, size_t calls, gsl_rng *r, gsl_monte_vegas_state *s, double *result, double *abserr)¶
This routines uses the VEGAS Monte Carlo algorithm to integrate the function
fover thedim-dimensional hypercubic region defined by the lower and upper limits in the arraysxlandxu, each of sizedim. The integration uses a fixed number of function callscalls, and obtains random sampling points using the random number generatorr. A previously allocated workspacesmust be supplied. The result of the integration is returned inresult, with an estimated absolute errorabserr. The result and its error estimate are based on a weighted average of independent samples. The chi-squared per degree of freedom for the weighted average is returned via the state struct component,s->chisq, and must be consistent with 1 for the weighted average to be reliable.
-
void gsl_monte_vegas_free(gsl_monte_vegas_state *s)¶
This function frees the memory associated with the integrator state
s.
The VEGAS algorithm computes a number of independent estimates of the
integral internally, according to the iterations parameter
described below, and returns their weighted average. Random sampling of
the integrand can occasionally produce an estimate where the error is
zero, particularly if the function is constant in some regions. An
estimate with zero error causes the weighted average to break down and
must be handled separately. In the original Fortran implementations of
VEGAS the error estimate is made non-zero by substituting a small
value (typically 1e-30). The implementation in GSL differs from
this and avoids the use of an arbitrary constant—it either assigns
the value a weight which is the average weight of the preceding
estimates or discards it according to the following procedure,
current estimate has zero error, weighted average has finite error
The current estimate is assigned a weight which is the average weight of the preceding estimates.
current estimate has finite error, previous estimates had zero error
The previous estimates are discarded and the weighted averaging procedure begins with the current estimate.
current estimate has zero error, previous estimates had zero error
The estimates are averaged using the arithmetic mean, but no error is computed.
The convergence of the algorithm can be tested using the overall chi-squared value of the results, which is available from the following function:
-
double gsl_monte_vegas_chisq(const gsl_monte_vegas_state *s)¶
This function returns the chi-squared per degree of freedom for the weighted estimate of the integral. The returned value should be close to 1. A value which differs significantly from 1 indicates that the values from different iterations are inconsistent. In this case the weighted error will be under-estimated, and further iterations of the algorithm are needed to obtain reliable results.
-
void gsl_monte_vegas_runval(const gsl_monte_vegas_state *s, double *result, double *sigma)¶
This function returns the raw (unaveraged) values of the integral
resultand its errorsigmafrom the most recent iteration of the algorithm.
The VEGAS algorithm is highly configurable. Several parameters can be changed using the following two functions.
-
void gsl_monte_vegas_params_get(const gsl_monte_vegas_state *s, gsl_monte_vegas_params *params)¶
This function copies the parameters of the integrator state into the user-supplied
paramsstructure.
-
void gsl_monte_vegas_params_set(gsl_monte_vegas_state *s, const gsl_monte_vegas_params *params)¶
This function sets the integrator parameters based on values provided in the
paramsstructure.
Typically the values of the parameters are first read using
gsl_monte_vegas_params_get(), the necessary changes are made to
the fields of the params structure, and the values are copied
back into the integrator state using
gsl_monte_vegas_params_set(). The functions use the
gsl_monte_vegas_params structure which contains the following
fields:
-
type gsl_monte_vegas_params¶
-
double alpha¶
The parameter
alphacontrols the stiffness of the rebinning algorithm. It is typically set between one and two. A value of zero prevents rebinning of the grid. The default value is 1.5.
-
size_t iterations¶
The number of iterations to perform for each call to the routine. The default value is 5 iterations.
-
int stage¶
Setting this determines the stage of the calculation. Normally,
stage = 0which begins with a new uniform grid and empty weighted average. Calling VEGAS withstage = 1retains the grid from the previous run but discards the weighted average, so that one can “tune” the grid using a relatively small number of points and then do a large run withstage = 1on the optimized grid. Settingstage = 2keeps the grid and the weighted average from the previous run, but may increase (or decrease) the number of histogram bins in the grid depending on the number of calls available. Choosingstage = 3enters at the main loop, so that nothing is changed, and is equivalent to performing additional iterations in a previous call.
-
int mode¶
The possible choices are
GSL_VEGAS_MODE_IMPORTANCE,GSL_VEGAS_MODE_STRATIFIED,GSL_VEGAS_MODE_IMPORTANCE_ONLY. This determines whether VEGAS will use importance sampling or stratified sampling, or whether it can pick on its own. In low dimensions VEGAS uses strict stratified sampling (more precisely, stratified sampling is chosen if there are fewer than 2 bins per box).
-
int verbose¶
-
FILE *ostream¶
These parameters set the level of information printed by VEGAS. All information is written to the stream
ostream. The default setting ofverboseis-1, which turns off all output. Averbosevalue of0prints summary information about the weighted average and final result, while a value of1also displays the grid coordinates. A value of2prints information from the rebinning procedure for each iteration.
-
double alpha¶
The above fields and the chisq value can also be accessed
directly in the gsl_monte_vegas_state but such use is
deprecated.
Examples¶
The example program below uses the Monte Carlo routines to estimate the value of the following 3-dimensional integral from the theory of random walks,

The analytic value of this integral can be shown to be
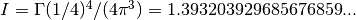 . The integral gives
the mean time spent at the origin by a random walk on a body-centered
cubic lattice in three dimensions.
. The integral gives
the mean time spent at the origin by a random walk on a body-centered
cubic lattice in three dimensions.
For simplicity we will compute the integral over the region
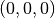 to
to  and multiply by 8 to obtain the
full result. The integral is slowly varying in the middle of the region
but has integrable singularities at the corners ,
and multiply by 8 to obtain the
full result. The integral is slowly varying in the middle of the region
but has integrable singularities at the corners ,
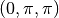 ,
, 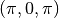 and
and 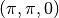 . The
Monte Carlo routines only select points which are strictly within the
integration region and so no special measures are needed to avoid these
singularities.
. The
Monte Carlo routines only select points which are strictly within the
integration region and so no special measures are needed to avoid these
singularities.
#include <stdlib.h>
#include <gsl/gsl_math.h>
#include <gsl/gsl_monte.h>
#include <gsl/gsl_monte_plain.h>
#include <gsl/gsl_monte_miser.h>
#include <gsl/gsl_monte_vegas.h>
/* Computation of the integral,
I = int (dx dy dz)/(2pi)^3 1/(1-cos(x)cos(y)cos(z))
over (-pi,-pi,-pi) to (+pi, +pi, +pi). The exact answer
is Gamma(1/4)^4/(4 pi^3). This example is taken from
C.Itzykson, J.M.Drouffe, "Statistical Field Theory -
Volume 1", Section 1.1, p21, which cites the original
paper M.L.Glasser, I.J.Zucker, Proc.Natl.Acad.Sci.USA 74
1800 (1977) */
/* For simplicity we compute the integral over the region
(0,0,0) -> (pi,pi,pi) and multiply by 8 */
double exact = 1.3932039296856768591842462603255;
double
g (double *k, size_t dim, void *params)
{
(void)(dim); /* avoid unused parameter warnings */
(void)(params);
double A = 1.0 / (M_PI * M_PI * M_PI);
return A / (1.0 - cos (k[0]) * cos (k[1]) * cos (k[2]));
}
void
display_results (char *title, double result, double error)
{
printf ("%s ==================\n", title);
printf ("result = % .6f\n", result);
printf ("sigma = % .6f\n", error);
printf ("exact = % .6f\n", exact);
printf ("error = % .6f = %.2g sigma\n", result - exact,
fabs (result - exact) / error);
}
int
main (void)
{
double res, err;
double xl[3] = { 0, 0, 0 };
double xu[3] = { M_PI, M_PI, M_PI };
const gsl_rng_type *T;
gsl_rng *r;
gsl_monte_function G = { &g, 3, 0 };
size_t calls = 500000;
gsl_rng_env_setup ();
T = gsl_rng_default;
r = gsl_rng_alloc (T);
{
gsl_monte_plain_state *s = gsl_monte_plain_alloc (3);
gsl_monte_plain_integrate (&G, xl, xu, 3, calls, r, s,
&res, &err);
gsl_monte_plain_free (s);
display_results ("plain", res, err);
}
{
gsl_monte_miser_state *s = gsl_monte_miser_alloc (3);
gsl_monte_miser_integrate (&G, xl, xu, 3, calls, r, s,
&res, &err);
gsl_monte_miser_free (s);
display_results ("miser", res, err);
}
{
gsl_monte_vegas_state *s = gsl_monte_vegas_alloc (3);
gsl_monte_vegas_integrate (&G, xl, xu, 3, 10000, r, s,
&res, &err);
display_results ("vegas warm-up", res, err);
printf ("converging...\n");
do
{
gsl_monte_vegas_integrate (&G, xl, xu, 3, calls/5, r, s,
&res, &err);
printf ("result = % .6f sigma = % .6f "
"chisq/dof = %.1f\n", res, err, gsl_monte_vegas_chisq (s));
}
while (fabs (gsl_monte_vegas_chisq (s) - 1.0) > 0.5);
display_results ("vegas final", res, err);
gsl_monte_vegas_free (s);
}
gsl_rng_free (r);
return 0;
}
With 500,000 function calls the plain Monte Carlo algorithm achieves a
fractional error of 1%. The estimated error sigma is roughly
consistent with the actual error–the computed result differs from
the true result by about 1.4 standard deviations:
plain ==================
result = 1.412209
sigma = 0.013436
exact = 1.393204
error = 0.019005 = 1.4 sigma
The MISER algorithm reduces the error by a factor of four, and also correctly estimates the error:
miser ==================
result = 1.391322
sigma = 0.003461
exact = 1.393204
error = -0.001882 = 0.54 sigma
In the case of the VEGAS algorithm the program uses an initial warm-up run of 10,000 function calls to prepare, or “warm up”, the grid. This is followed by a main run with five iterations of 100,000 function calls. The chi-squared per degree of freedom for the five iterations are checked for consistency with 1, and the run is repeated if the results have not converged. In this case the estimates are consistent on the first pass:
vegas warm-up ==================
result = 1.392673
sigma = 0.003410
exact = 1.393204
error = -0.000531 = 0.16 sigma
converging...
result = 1.393281 sigma = 0.000362 chisq/dof = 1.5
vegas final ==================
result = 1.393281
sigma = 0.000362
exact = 1.393204
error = 0.000077 = 0.21 sigma
If the value of chisq had differed significantly from 1 it would
indicate inconsistent results, with a correspondingly underestimated
error. The final estimate from VEGAS (using a similar number of
function calls) is significantly more accurate than the other two
algorithms.
References and Further Reading¶
The MISER algorithm is described in the following article by Press and Farrar,
W.H. Press, G.R. Farrar, Recursive Stratified Sampling for Multidimensional Monte Carlo Integration, Computers in Physics, v4 (1990), pp190–195.
The VEGAS algorithm is described in the following papers,
G.P. Lepage, A New Algorithm for Adaptive Multidimensional Integration, Journal of Computational Physics 27, 192–203, (1978)
G.P. Lepage, VEGAS: An Adaptive Multi-dimensional Integration Program, Cornell preprint CLNS 80-447, March 1980
Footnotes
- 1
The previous method of accessing these fields directly through the
gsl_monte_miser_statestruct is now deprecated.